
今天的內容很多所以分成了上下篇,上篇主要在講述TensorRT的概念以及使用ONNX模型等技巧,下篇會進入TensorRT應用的部分。
*本文由RS components 贊助發表,轉載自DesignSpark部落格原文連結
目錄
- TensorRT
- TensorRT 的優化方式
- TensorRT vs Tensorflow Lite
- TensorRT建構流程
- ONNX (Open Neural Network Exchange)
- Jetson Nano安裝TensorRT.
- PyTorch 匯出 ONNX.
- 透過ONNX RUNTIME運行ONNX Model
- 使用TensorRT運行ONNX
- PyTorch使用TensorRT最簡單的方式
- YOLOv5使用TensorRT引擎方式
- 結語
TensorRT
TensorRT是由 NVIDIA 所推出的深度學習加速引擎 (以下簡稱trt ),主要的目的是用在加速深度學習的 Inference,按照官方提出TensorRT比CPU執行快40倍的意思,就像是YOLOv5針對一張圖片進行推論用CPU的話大概是1秒,如果用上TensorRT的話可能就只要0.025秒而已,這種加速是非常明顯的!而這種加速大部分都是運用的邊緣裝置上 ( Edge Device ),由於邊緣裝置上的效能沒有一般電腦來的好,所以往往需要這種軟體加速。
TensorRT 的優化方式

TensorRT主要的優化過程有這些: Precision Calibration、Layer & Tensor Fusion、Kernel Auto-Tuning、Dynamic Tensor Memory、Multi-Stream Execution,今天會介紹前兩種,後面三種比較底層資訊也比較少所以就先不介紹了。
降低資料精準度(Precision Calibration)
在官網上有提到trt支援INT8 和 FP16兩種更簡化的精度格式。神經網路模型再進行訓練的時候都需要將數據轉成張量 ( Tensor ),而 Tensor 的資料型態為FP32 ( 單經度浮點數),總共會耗費32個bit,而trt優化的FP16 ( 半經度浮點數 ) 則直接少一半,INT8又再少一半,在DLI的投影片中有提到 INT8所需的記憶體比FP32小了61%。但減少位元數雖然可以大幅降低模型的大小,但相對而言你的精準度勢必會下降,所以NVDIA也有提出了相關的解決方法。
對模型進行重構與優化(Layer & Tensor Fusion)
1.第一步先刪除沒有使用到的輸出層
2.垂直優化:由於CUDA會在每一層輸入的時候啟動,而這個垂直優化就是透過將常使用的層作合併,像圖中將Conv、bias、relu合併為CBR,減少CUDA啟動關閉的次數來達到時間上的縮減。

3.水平優化:理論同上,如果同層其他分支也在運作一樣的架構則直接合併,要注意的地方是合併成同一層之後輸出必須要做分割,再輸出到不同層去。

TensorRT vs Tensorflow Lite
如同Tensorflow lite ( 以下簡稱 tflite ),他們都是用來加速的方法。他們倆者的主要差別在於trt是由NVIDIA推出的,如果使用NVIDIA的GPU來運作效果會比tflite還要快很多,但其實市面上還有很多設備是只有CPU或是沒有CUDA核心的GPU,那些設備就比較適合用tflite;我們今天的主角是Jetson Nano,它最大的優勢在於它擁有CUDA核心的GPU,能夠進行trt加速,它將會比其他邊緣裝置更適合用來開發AI相關的專案。
TensorRT建構流程
- ONNX parser:將模型轉換成ONNX的模型格式。
- Builder:將模型導入TensorRT並且建構TensorRT的引擎。
- Engine:引擎會接收輸入值並且進行Inference跟輸出。
- Logger:負責記錄用的,會接收各種引擎在Inference時的訊息。
基本上TensorRT的運作都需要先轉換成ONNX才行,那ONNX到底是什麼東西呢?
ONNX (Open Neural Network Exchange)
好玩的地方在於ONNX的名稱為Open Neural Network Exchange ( 神經網路之間的開源交流),所以其實從名稱來看就知道,他是一個標準化神經網路模型的工具。

因為現在大部分的硬體加速都是倚賴NVIDIA的GPU,幾乎就是AI世界的龍頭,所以其實各大框架都陸續支援trt的SDK,但是各大框架為了獨特性都會推出自己的模型格式,像是 PyTorch輸出模型格式為.pt、.pth而Tnesorflow輸出的模型為 .h5,各種不同的檔案格式對於trt來說要優化他們會很辛苦,所以ONNX推出了一個統一的模型格式 ONNX,透過ONNX的檔案格式便可以導入TensorRT來進行加速;對了,目前較熱門的Tensorflow也有合作哦!只是不是透過ONNX的方式來轉換。
Jetson Nano安裝TensorRT
安裝方法有提供兩種,第一種是官方的安裝方法,第二種是直接安裝我的映像檔,如果是體驗導向我會建議直接安裝我的映像檔。
1. 官方作法
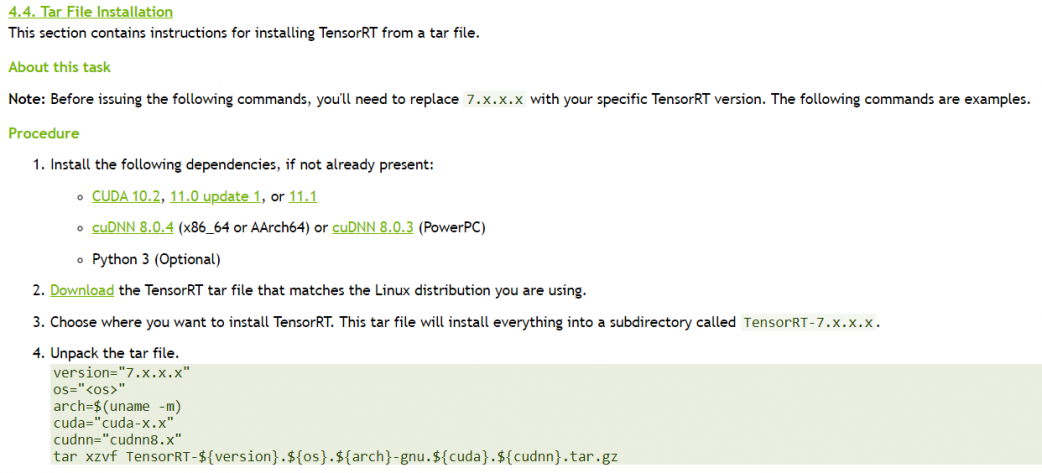
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-tar
詳細的安裝步驟可以參考官方網站,要注意的是 TensorRT 7 是還沒有支援 Jetson 系列的,所以可以考慮安裝6。這個會耗費大量的時間,所以另一個方法是使用我提供的映像檔,其中已經包含 tensorrt 以及 uff 等相關套件。
2. 我的映像檔
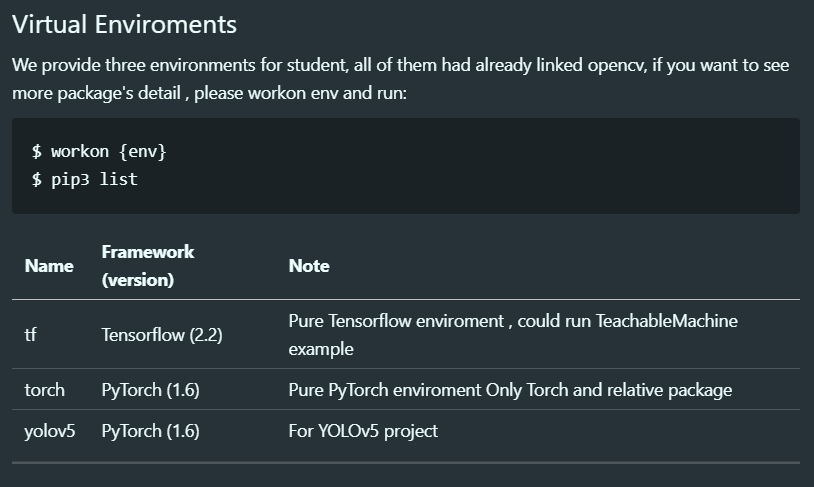
連結如下:
https://www.dropbox.com/sh/rgxe2uf8wodb3bx/AAAcBg0QnAnZIlgaQAD63eOza?dl=0。要注意的地方用SanDisk的SD卡可能會有容量不夠的問題,建議使用Samsung 64GB以上的記憶卡。
將TensorRT連結到virtualenv
完成之後進到虛擬環境中應該就可以看到虛擬環境連結到tensorrt了。
PyTorch 匯出 ONNX
官方介紹文件連結如下:https://pytorch.org/docs/stable/onnx.html。PyTorch為了追上AI加速的NVIDIA列車,早已在框架中也包含了ONNX模型匯出的函式庫,但是還是需要先安裝ONNX才行,基本上我們只要透過導入ONNX函式庫並且透過torch.onnx.export即可匯出ONNX的模型。
Torch.onnx.export
其中model就是要轉換的模型;args可以想像成是輸入的維度,以 [ batch , C , H , W ]為主,這邊順道提一下也有 dynamic_axes動態輸入維度的選項可以選擇,默認值export_param為True所以都會導出權重值;剩下的有興趣在去原廠的文件查看。
使用方法
使用onnx.export的方法也是非常的簡單,我們使用Alexnet來當作範例,這個是取自官方的文件,可以注意到他有定義輸入跟輸出的名稱,目的是為了後續調用方便:
因為匯出的時候選擇verbose=True所以會將轉換的進度打印出來:
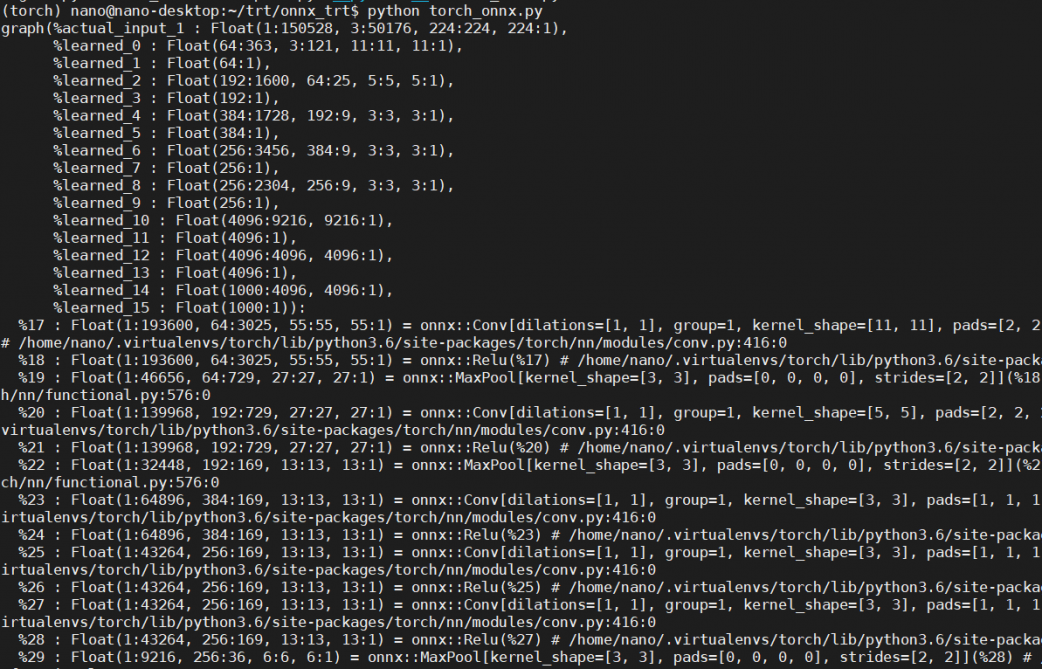
這邊直接引用原廠文件的內容:
The resulting alexnet.onnx is a binary protobuf file which contains both the network structure and parameters of the model you exported (in this case, AlexNet). The keyword argument verbose=True causes the exporter to print out a human-readable representation of the network:
匯出的是一個二進制的protobuf的檔案,這是一種序列化的資料結構,ONNX會依靠這種資料結構來描述模型檔案,在Caffe等AI框架也都是使用一樣的資料結構形式,那這個binary protobuf包含了神經網路的架構跟權重,之前在開發PyTorch的時候是被建議儲存權重就好,架構要再另外寫,有時候會覺得稍微有一點麻煩,但是ONNX就改善這個問題了,他只需要導入檔案,模型的架構也都包含在其中不用額外建構了。
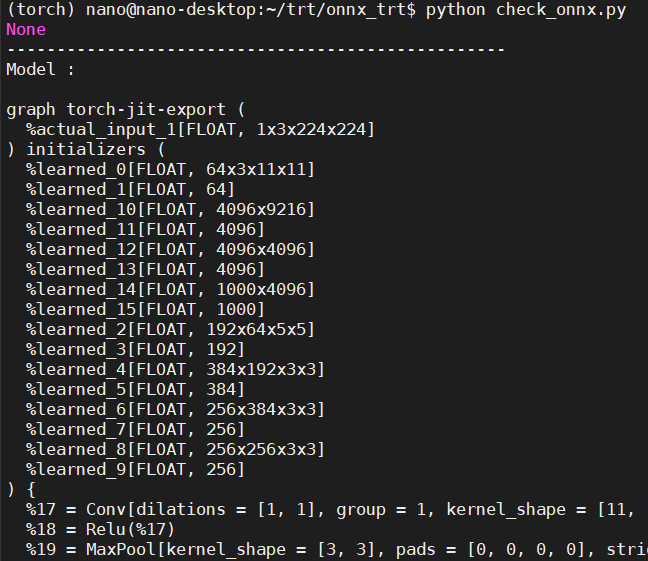
檢查ONNX模型
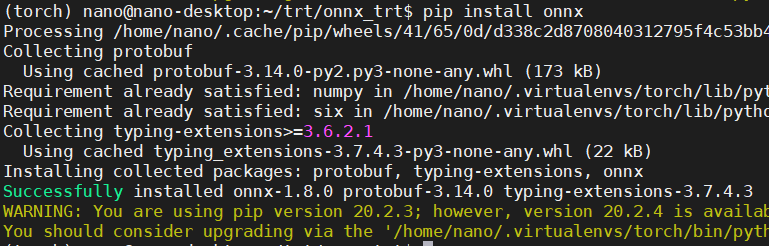
首先我們要先安裝ONNX套件:
我的結果如下,可以注意到它會連同protobuf也一起安裝了。
剛剛執行完程式之後應該可以注意到檔案中已經多了一個alexnet.onnx,這個就是我們匯出成功的檔案,接著可以透過下列程式來確認:
圖形化顯示ONNX模型
廣大的網友們都推薦使用Netron這套軟體,直接透過PyPI即可安裝。

透過下列程式碼可以查看圖形化模型,執行完他會產生一個localhost來存放圖檔:

點擊Block便可以獲得相關資訊:
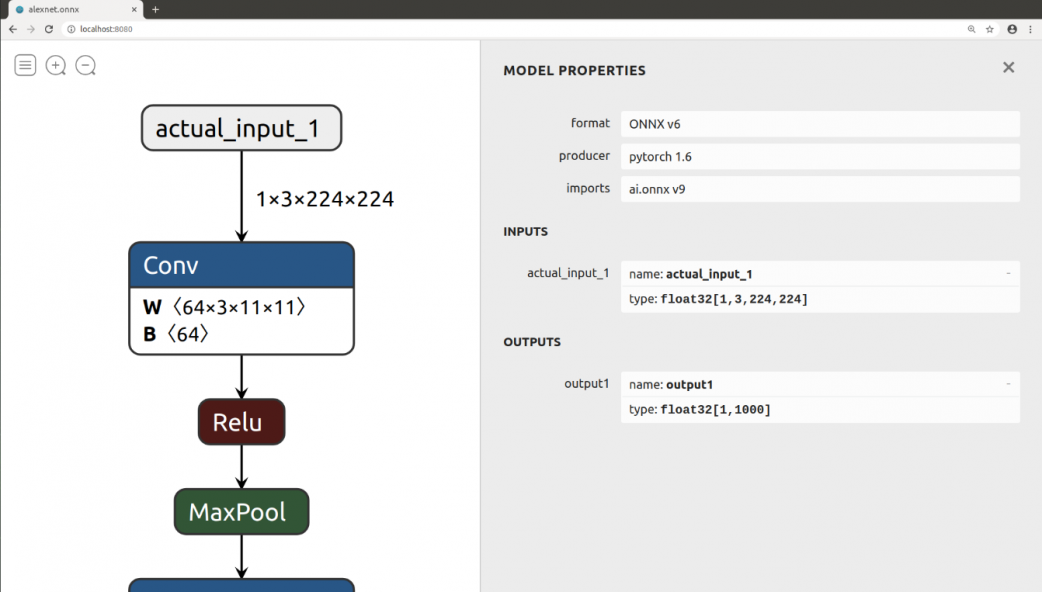
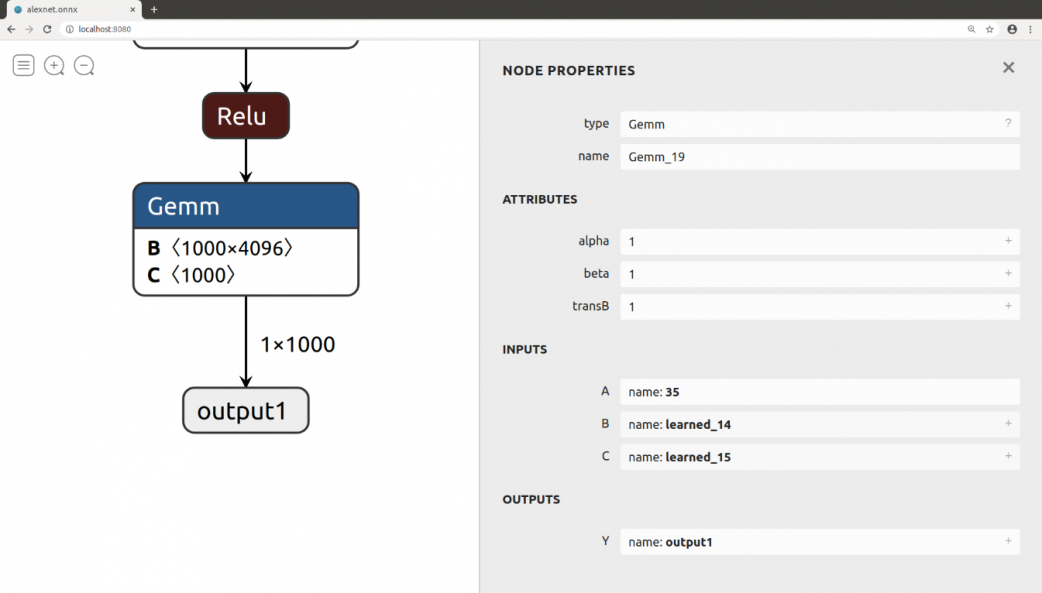
可以看到我們當初在匯出的時候宣告了輸入的維度所以這邊輸入維度也是顯示當初設定的數值,在右側也可以看到相關資訊,包括連PyTorch的版本資訊也有顯示出來。
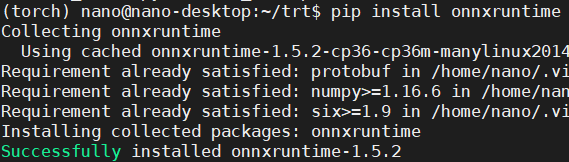
透過ONNX RUNTIME運行ONNX Model
獲得到ONNX後要怎麼執行呢?他自己也提供了一個平台(框架)可以運行,叫做ONNX RUNTIME ( 以下簡稱 ORT ),他兼容了許多硬體加速平台,像是今天的主角TensorRT,還有Intel的OpenVINO等等的,也因為ONNX模型的關係,所以他也兼融了各大平台的模型,等於說使用者透過TF、PyTorch建構的神經網路模型,都可以再ORT上進行推論跟訓練。
先來安裝ONNX RUN TIME:
使用ORT 來進行模型的推論之範例程式:
基本上有兩個重點,第一個是導入需要用InferenceSession接著直接用run即可進行推論;第二個重點在於run的引數是要用字典形式來輸入,所以需要給定字典的欄位名稱並且告知輸入的數值。
ORT 運行 AlexNet
開始之前我先寫了一個整理顯示資訊的程式,檔名為log.py,特別將文字改了顏色:
接著開啟一個新檔案 3_run_onnx.py將函式庫以及剛剛寫的log導入:
先讀取資料並且轉換成對應格式:
宣告ORT的Session並且不同於範例的做法我直接取得第一層的名稱,這個作法是為了避免打錯字或是忘記自己當初定義的名稱:
獲得結果後將標籤給顯示出來:
運行結果如下:
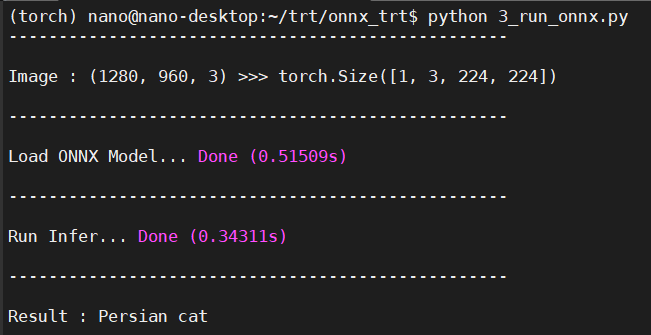
ORT運行.onnx與PyTorch運行.pth速度差異
這邊我將輸出的數值做了softmax縮限在 [0, 1]之間。
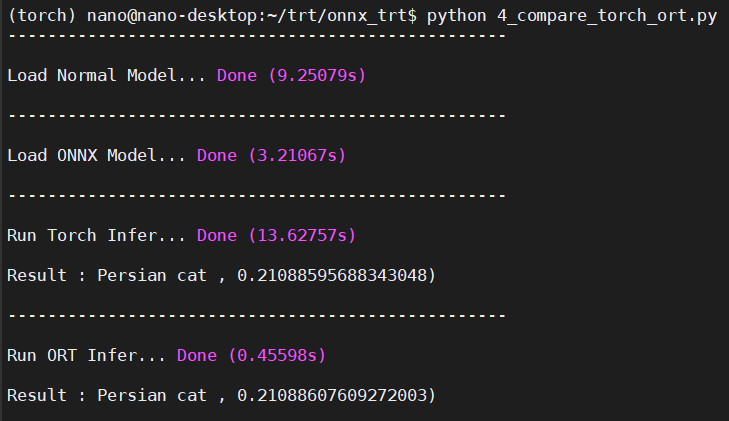
稍微整理一下,可以發現光ONNX與PyTorch模型載入速度就有顯著的差異了,在Inference的時間上也有將近45倍的差距!由此可知ONNX確實能夠簡化模型並且加速Inference的時間,接著要使用TensorRT引擎來運行ONNX模型!
參考文章
- What is the difference between tflite and tensorRT?
- TensorRT(1)-介绍-使用-安装
- TensorRT-Optimization-Principle
- Speeding up Deep Learning Inference Using TensorFlow, ONNX, and TensorRT
*本文由RS components 贊助發表,轉載自DesignSpark部落格原文連結 (本篇文章完整範例程式請至原文處下載)



